How to build a zero-ETL DynamoDB integration with OpenSearch Service using AWS CDK

AWS OpenSearch Service is the managed service offering for deploying search and analytics suites - specifically OpenSearch or Elasticsearch.
At AWS re:Invent 2023, it was announced that people who are using DynamoDB can now ingest their data into OpenSearch, to take advantage of the powerful features that it provides.
The underlying mechanism that provides this functionality is Amazon OpenSearch Ingestion in combination with S3 exports and DynamoDB streams. It essentially allows developers to push data into DynamoDB tables as normal and this data will be automatically ingested (and updated!) into OpenSearch.
As part of the pipeline, it can also be separately backed up to S3 as well which is useful for re-ingesting in the future if required.
This is an extremely powerful coupling of services, and a cost-effective way to ingest data into OpenSearch. Let’s take a look at how we can achieve this using AWS CDK.
✍️ Define some CDK
There are a few things that we’re going to need to provision in order to set up our ingestion pipeline - although I’ll assume that you have an existing OpenSearch Domain running.
DynamoDB Table
Let’s spin up our DynamoDB table that we’ll push items in to.
const dynamoDbTable = new cdk.aws_dynamodb.TableV2(this, "DynamoDB Table", {
partitionKey: {
name: "id",
type: cdk.aws_dynamodb.AttributeType.STRING
},
sortKey: {
name: "timestamp",
type: cdk.aws_dynamodb.AttributeType.NUMBER,
},
tableName: "opensearch-ingestion-table",
billing: cdk.aws_dynamodb.Billing.onDemand(),
pointInTimeRecovery: true,
dynamoStream: cdk.aws_dynamodb.StreamViewType.NEW_IMAGE,
});
Some things to note here:
- We need to ensure that Point in time recovery (PITR) is enabled, as this is required for the pipeline integration.
- DynamoDB streams also need to be enabled to capture any changes to items that also get subsequently ingested into OpenSearch.
S3 Bucket and IAM Role
Next up is the S3 bucket that we’ll use to backup the raw events that get consumed by the OpenSearch pipeline, and the IAM role that will be assumed by the pipeline:
const s3BackupBucket = new cdk.aws_s3.Bucket(
this,
"OpenSearch DynamoDB Ingestion Backup S3 Bucket", {
blockPublicAccess: cdk.aws_s3.BlockPublicAccess.BLOCK_ALL,
bucketName: "opensearch-ddb-ingestion-backup",
encryption: cdk.aws_s3.BucketEncryption.S3_MANAGED,
enforceSSL: true,
versioned: true,
removalPolicy: cdk.RemovalPolicy.RETAIN,
}
);
const openSearchIntegrationPipelineIamRole = new cdk.aws_iam.Role(
this,
"OpenSearch Ingestion Pipeline Role - DynamoDB", {
roleName: "OpenSearch Ingestion Pipeline Role - DynamoDB",
assumedBy: new cdk.aws_iam.ServicePrincipal(
"osis-pipelines.amazonaws.com"
),
inlinePolicies: {
openSearchIntegrationPipelineIamRole: new cdk.aws_iam.PolicyDocument({
statements: [
new cdk.aws_iam.PolicyStatement({
actions: ["es:DescribeDomain"],
resources: [
`arn:aws:es:eu-west-1:*:domain/${openSearchDomain.domainName}`,
],
effect: cdk.aws_iam.Effect.ALLOW,
}),
new cdk.aws_iam.PolicyStatement({
actions: ["es:ESHttp*"],
resources: [
`arn:aws:es:eu-west-1:*:domain/${openSearchDomain.domainName}`,
],
effect: cdk.aws_iam.Effect.ALLOW,
}),
],
}),
},
}
);
openSearchIntegrationPipelineIamRole.addManagedPolicy(
cdk.aws_iam.ManagedPolicy.fromAwsManagedPolicyName(
"AmazonDynamoDBFullAccess"
)
);
openSearchIntegrationPipelineIamRole.addManagedPolicy(
cdk.aws_iam.ManagedPolicy.fromAwsManagedPolicyName("AmazonS3FullAccess")
);
When it comes to the S3 bucket, it’s fairly standard - no public access, encrypted at rest and versioned.
With the IAM Role, we need to allow the role to be assumed by the OpenSearch Ingestion Service (OSIS) pipelines. We then provide it with some specific OpenSearch Service permissions, before adding DynamoDB and S3 access - these could be tailored better to adhere to the principle of least privilege but for ease of showcasing the functionality, I’ve just defaulted to the managed full access policies.
OpenSearch Service Pipeline
Finally, we need to define the pipeline construct and the configuration for said pipeline.
The configuration for the pipeline is a data-prepper feature of OpenSearch and the specific documentation for DynamoDB (and the API) can be found here - take a look at the other sources and sinks that are possible out of the box.
Now you’ll probably notice that the config is defined as YAML, but since we’re defining it as infrastructure as code using TypeScript and want some dynamic variables in there, I just wrapped it up in a separate function that just interpolates strings.
const generateTemplate = (
dynamoDbTable: cdk.aws_dynamodb.TableV2,
s3BucketName: string,
iamRoleArn: string,
openSearchHost: string,
indexName: string,
indexMapping: string
) => `
version: "2"
dynamodb-pipeline:
source:
dynamodb:
acknowledgments: true
tables:
- table_arn: "${dynamoDbTable.tableArn}"
# Remove the stream block if only export is needed
stream:
start_position: "LATEST"
# Remove the export block if only stream is needed
export:
s3_bucket: "${s3BucketName}"
s3_region: "eu-west-1"
s3_prefix: "${dynamoDbTable.tableName}/"
aws:
sts_role_arn: "${iamRoleArn}"
region: "eu-west-1"
sink:
- opensearch:
hosts:
[
"https://${openSearchHost}",
]
index: "${indexName}"
index_type: "custom"
template_content: |
${indexMapping}
document_id: '\${getMetadata("primary_key")}'
action: '\${getMetadata("opensearch_action")}'
document_version: '\${getMetadata("document_version")}'
document_version_type: "external"
bulk_size: 4
aws:
sts_role_arn: "${iamRoleArn}"
region: "eu-west-1"
`;
This really defines what we want our ingestion pipeline to do. This is pretty much the example config that is in the documentation, with a few critical tweaks.
For the source portion of the config, we’re ultimately:
- Defining that DynamoDB is our source, which table we want to ingest and the position of the stream to start from.
- As well as ingesting the stream into OpenSearch, we also want to export to S3 as a form of a backup, so we define the target bucket.
- Finally, we’re setting the IAM role that we want the ingestion pipeline to use. Note: the documentation is specific about what permissions and policies need to be attached to it, so make sure to reference them!
For the sink configuration:
- Pointing it to our OpenSearch domain cluster via setting the host.
- Specifying the index name, what type it is and critically, we’re also setting template_content which is essentially the index mapping - but more on this below.
- Setting various document related metadata which are utilising internal intrinsic functions here that are unique to the DynamoDB integration along with the maximum bulk size of requests to be sent to OpenSearch in MB.
- Then again, just specifying the IAM role for the sink portion of the pipeline to use.
Something that is incredible powerful when using OpenSearch is if you know the structure of the data you’re going to be ingesting ahead of time, meaning you can define the index template (or mapping) - specifically setting the data types for each field of the document.
In this case, we’re defining the template_content which is exactly that in a JSON-representation.
const indexName = "log-events";
const indexMapping = {
settings: {
number_of_shards: 1,
number_of_replicas: 0,
},
mappings: {
properties: {
id: {
type: "keyword",
},
timestamp: {
type: "date",
format: "epoch_millis",
},
},
},
};
const pipelineConfigurationBody = generateTemplate(
dynamoDbTable,
backupS3Bucket.bucketName,
openSearchPipelineRole.roleArn,
openSearchDomain.domainEndpoint,
indexName,
JSON.stringify(indexMapping)
);
For the purposes of a demo, I’ve just kept this fairly trivial with only two properties - but you can see how it can be easily extended in this case.
Finally, we bring all of this together by creating the OSIS pipeline resource itself. There isn’t a L2 CDK construct for this, so we’re just using the lower-level CloudFormation pipeline construct, but it works perfectly:
const cloudwatchLogsGroup = new cdk.aws_logs.LogGroup(
scope,
"OpenSearch DynamoDB Ingestion Pipeline Log Group", {
logGroupName: `/aws/vendedlogs/OpenSearchIntegration/opensearch-dynamodb-ingestion-pipeline`,
retention: cdk.aws_logs.RetentionDays.ONE_MONTH,
}
);
const cfnPipeline = new cdk.aws_osis.CfnPipeline(
scope,
"OpenSearch DynamoDB Ingestion Pipeline Configuration", {
maxUnits: 4,
minUnits: 1,
pipelineConfigurationBody: pipelineConfigurationBody,
pipelineName: "dynamodb-integration",
logPublishingOptions: {
cloudWatchLogDestination: {
logGroup: cloudwatchLogsGroup.logGroupName,
},
isLoggingEnabled: true,
},
}
);
As straightforward as defining our OpenSearch Compute Units (OCUs) boundaries that we want the pipeline to work within (these are the billable components within the ingestion pipelines), and setting the pipeline configuration that we’ve generated along with some additional CloudWatch logging for debugging and monitoring.
And now we’re ready to deploy!
🚀 Deploy!
Let’s deploy this example and see what it looks like in practice. Our CDK diff should resemble something like the following:
Resources
[+] AWS::DynamoDB::GlobalTable DynamoDB Table DynamoDBTable8EA388EE
[+] AWS::IAM::Role OpenSearch Ingestion Pipeline Role - DynamoDB OpenSearchIngestionPipelineRoleDynamoDBC974378B
[+] AWS::S3::Bucket OpenSearch DynamoDB Ingestion Backup S3 Bucket OpenSearchDynamoDBIngestionBackupS3Bucket017A2C31
[+] AWS::S3::BucketPolicy OpenSearch DynamoDB Ingestion Backup S3 Bucket/Policy OpenSearchDynamoDBIngestionBackupS3BucketPolicy4CA396B4
[+] AWS::Logs::LogGroup OpenSearch DynamoDB Ingestion Pipeline Log Group OpenSearchDynamoDBIngestionPipelineLogGroupEB6F0DB2
[+] AWS::OSIS::Pipeline OpenSearch DynamoDB Ingestion Pipeline Configuration OpenSearchDynamoDBIngestionPipelineConfiguration
Once the resources have deployed, we can test our ingestion by adding an item into the DynamoDB table that has just been provisioned - but let’s check the pipeline has been configured as expected.
Jump into the console and firstly into OpenSearch, navigate to the pipelines section and you should see your pipeline along with the configuration we’ve set up:
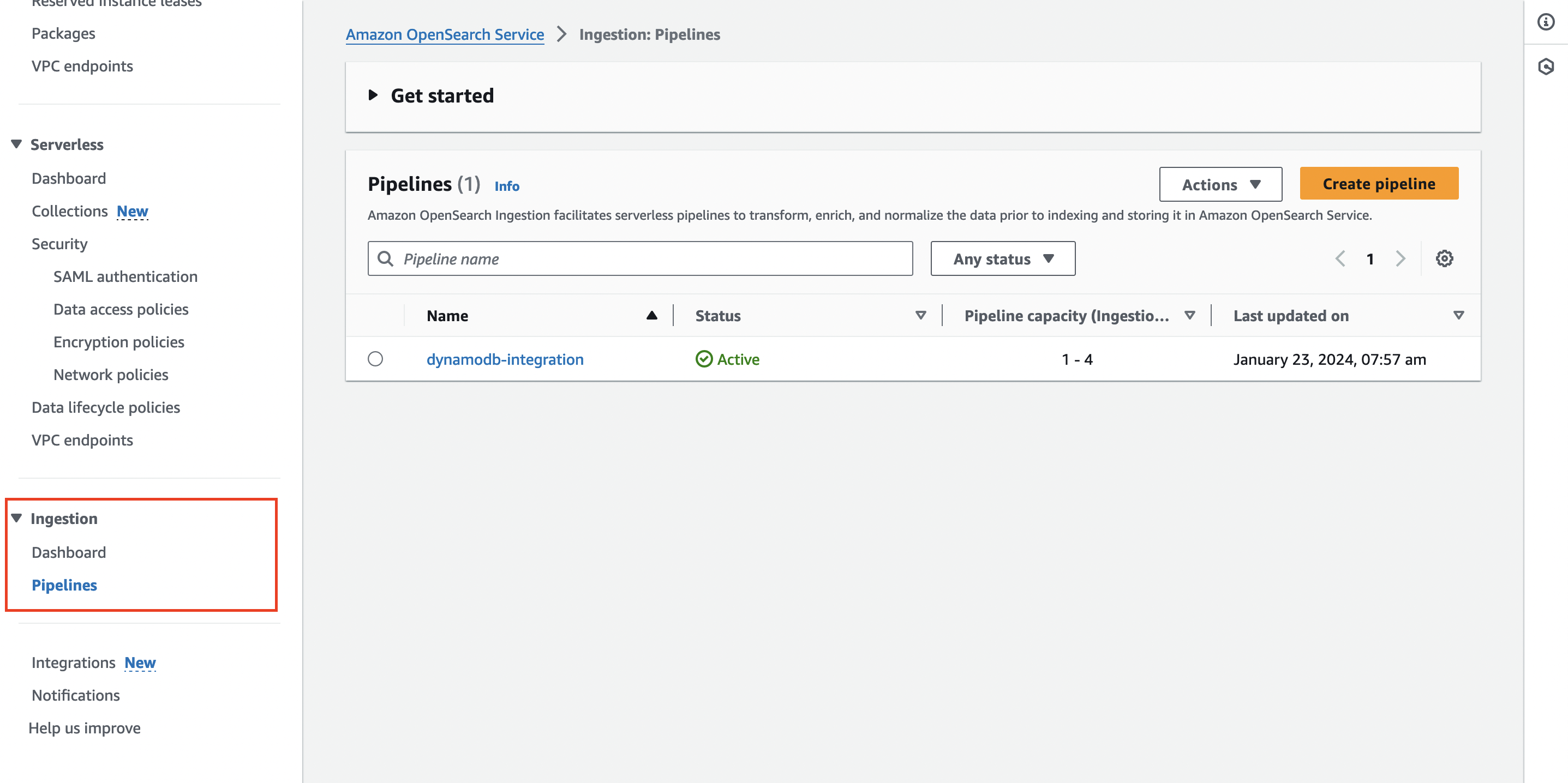
Can also verify this from the DynamoDB end of things, via the Integrations section of the tables as well:
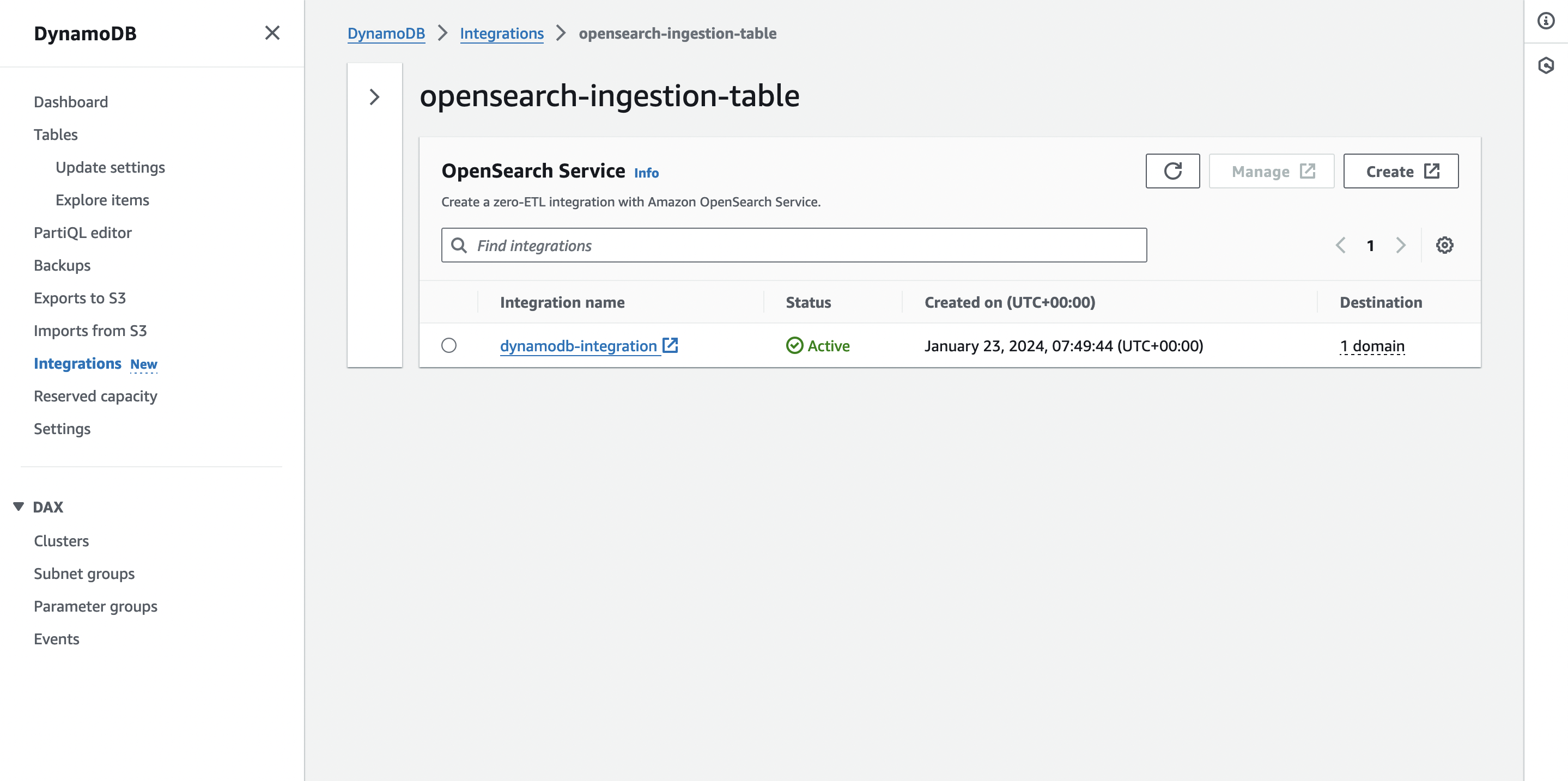
And that’s it! You can now put items into your DynamoDB table and they should be ingested.
Note: if you don’t see your index or any items ingested, jump into CloudWatch logs for the pipeline. If you’re pointing to an existing OpenSearch cluster, make sure to check the permissions and fine-grained access control are sufficient.
Conclusion
Remember to cdk destroy once you are complete to destroy the CloudFormation stack in order to avoid any unnecessary costs if you’re just testing this demo out!
- Combining the ease of the interface with DynamoDB with an ingestion pipeline into OpenSearch is incredibly powerful. If you’re already utilising DynamoDB, your application logic doesn’t need to change - it just needs to continue to write items to it as normal.
- The advantage of the OpenSearch Ingestion Service pipeline is that it can consume from your DynamoDB stream and also export to a S3 bucket too in order to keep a backup of your events/items in the case that you need to re-index in OpenSearch.
- You can specify how you wish to set the index up in OpenSearch in the pipeline itself, meaning you can have fine-grained control over the number of shards, replicas and the mapping structure - ensuring that the integration with DDB is optimised.
- It’s a cost-effective solution for users who don’t need to perform any additional transformation as part of their ingestion pipeline, i.e. you don’t necessarily need to use Kinesis (and it being quite costly!).
- Some cost optimisation can be applied to the pipelines in order to keep costs as low as possible depending on your use case, but that will come in a follow-up blog!
- Whilst there aren’t explicit L2 CDK constructs for some of the resources, the API is fairly straightforward to utilise.
- Be sure to check out the announcement along with some of the other linked documentation in there for the OSIS pipeline and DynamoDB table setup - happy searching!