How to build AWS State Machines using AWS CDK - Part II

In my previous blog in this mini-series, we walked through what step functions are used for, how they can be defined and then continued to define a basic one with a few building blocks in CDK. If you haven’t read it, check it out here.
Within this blog, we’re going to take a look at some of the other constructs and concepts that you can utilise within your state machine for optimisation and power-processing of data. We’re going to build on top of the existing state machine that we created last time and focus on the choice logic operator.
❓ What
As I described before, Step Function state machines have a plethora of low-level AWS service integrations that you can interface with directly - these are typically known as actions. They also have a bunch of different flow operations that you can apply to your state machine that allows finer control of what happens to the data that you’re passing in.
Examples of flow operations include:
- Choice (if/then-else logic)
- Parallel
- Map
- Wait
In the existing state machine that we’re going to build on top of for these examples, you might have noticed that we’re already defining a wait flow operation - so let’s enhance and add a few more for a prescriptive example.
✍️ Define some CDK
Picking up from where we left off last time, our final state machine CDK definition looked something like the following:
import * as cdk from "aws-cdk-lib";
import * as dynamodb from "aws-cdk-lib/aws-dynamodb";
import * as lambda from "aws-cdk-lib/aws-lambda";
import * as stepFunctions from "aws-cdk-lib/aws-stepfunctions";
import * as stepFunctionsTasks from "aws-cdk-lib/aws-stepfunctions-tasks";
const mockLambdaFunctionArn =
"arn:aws:lambda:us-east-1:12345:function:my-shiny-lambda-function";
const mockDdbTableArn =
"arn:aws:dynamodb:us-east-1:12345:table/my-shiny-dynamodb-table";
const lambdaFunction = lambda.Function.fromFunctionArn(
this,
"lambda-function",
mockLambdaFunctionArn
);
const dynamodbTable = dynamodb.Table.fromTableArn(
this,
"dynamo-db-table",
mockDdbTableArn
);
const processJob = new stepFunctionsTasks.LambdaInvoke(
this,
"state-machine-process-job-fn", {
lambdaFunction: lambdaFunction,
}
);
const wait10MinsTask = new stepFunctions.Wait(
this,
"state-machine-wait-job", {
time: stepFunctions.WaitTime.duration(cdk.Duration.minutes(10)),
}
);
const ddbWrite = new stepFunctionsTasks.DynamoPutItem(
this,
"ddb-write-job", {
item: {
uuid: stepFunctionsTasks.DynamoAttributeValue.fromString(
crypto.randomUUID()
),
timestamp: stepFunctionsTasks.DynamoAttributeValue.fromString(
new Date().toISOString()
),
},
table: dynamodbTable,
}
);
const stateMachineDefinition = processJob
.next(wait10MinsTask)
.next(ddbWrite);
const stateMachine = new stepFunctions.StateMachine(this, "state-machine", {
definitionBody: stepFunctions.DefinitionBody.fromChainable(
stateMachineDefinition
),
timeout: cdk.Duration.minutes(5),
stateMachineName: "ProcessAndReportJob",
});
So you can see from the above, within the CDK library, there is a specific aws-stepfunctions-tasks namespace that houses a lot of the actions that can be performed within a task block in state machines. These include things like Lambda invocations, DynamoDB put item operations, SQS enqueue item etc.
For the flow operations, we will be using the aws-stepfunctions namespace to perform some of this logical control that we want to achieve.
🔍 Choice
A choice flow operation is pretty much exactly as it is described. It’s an if/else statement that can apply conditional branching logic to your state machine in order to perform different actions depending on the input data that has been passed in.
Critically, this input data can either be at the top-level of the state machine (i.e. the state machine execution input) or it can be derived from other metadata that has been output from other steps (e.g. a response from a Lambda function invocation).
To keep this fairly simple, we’re going to just focus on the top-level execution input data and for demonstration purposes, it’s going to be a boolean value.
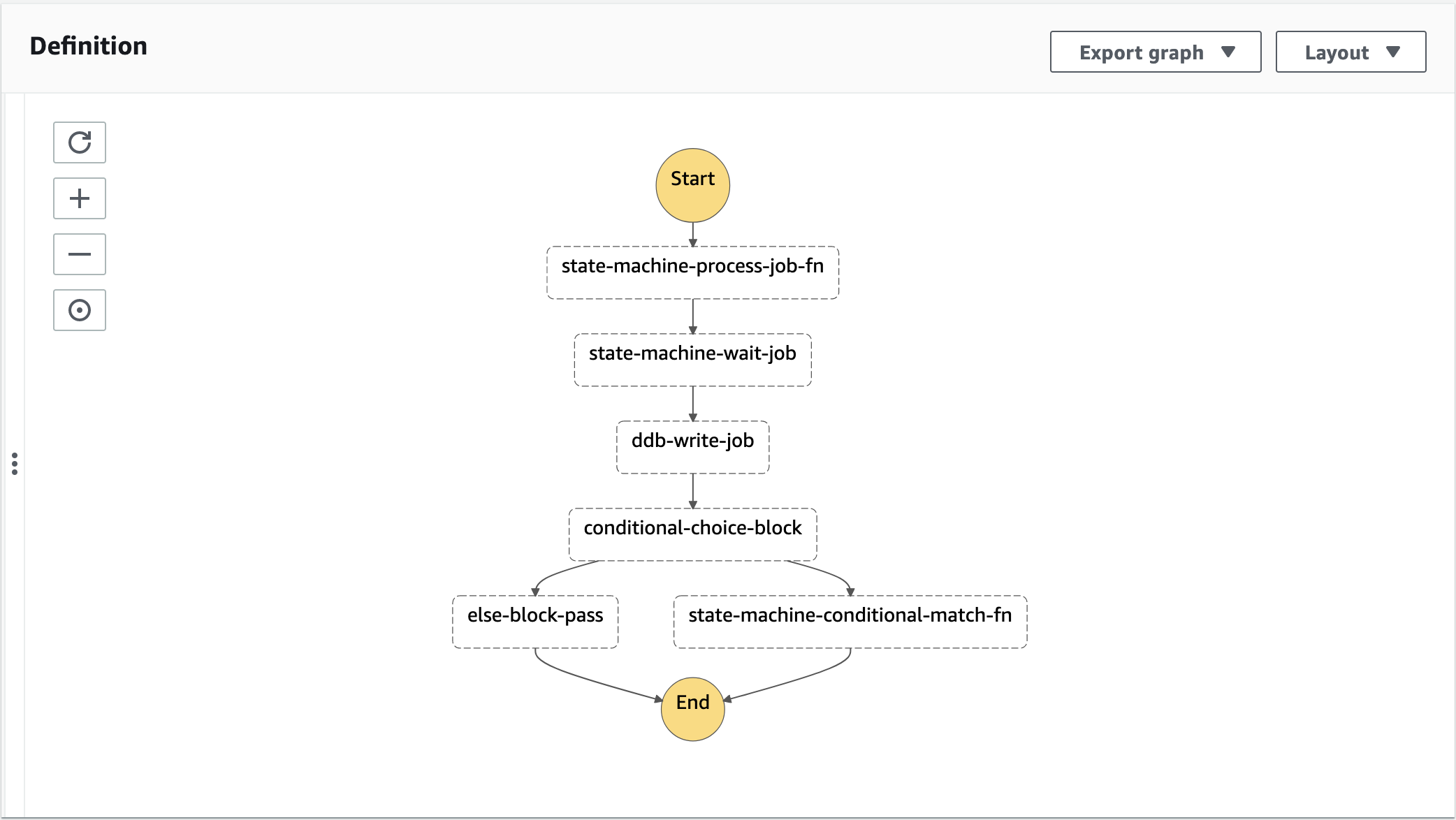
Firstly, we’re going to create our choice block construct along with the condition we want to evaluate:
const choiceStatement = new stepFunctions.Choice(
this,
"conditional-choice-block"
);
const choiceCondition = stepFunctions.Condition.booleanEquals(
"$.pass",
true
);
You can see in the snippet, the value we want to evaluate is pass but it has some slightly odd looking syntax. This is JSON path notation. Inputs & outputs to state machines and the individual workflows inside the state machine all flow using JSON.
JSON path is how we can reference different variables and mutate the inputs/outputs if we need to. You can read more about how inputs/outputs work within state machines here.
AWS also have some tooling available for learning & testing the various paths, parameters etc. within state machines which I will link at the end!
This is a pretty important concept to understand, as it is used heavily throughout any implementation of state machines you might have for managing state transitions! You’ll even notice in one of the upcoming snippets that we have to modify existing action operations within our state machine to cater for how these inputs/outputs work.
Continuing on! Next, we need to define what actions we want to perform in each of our conditional branches - for our if branch, we’re going to invoke a Lambda function and in the else branch, we’re just going to have a Pass state. Let’s set this up:
const conditionalMatchLambdaFunction = new stepFunctionsTasks.LambdaInvoke(
this,
"state-machine-conditional-match-fn", {
lambdaFunction: lambdaFunction,
}
);
const elsePassStep = new stepFunctions.Pass(this, "else-block-pass");
Finally, we need to update our state machine definition with all of these references we have just created using the familiar chaining methods you might have seen before:
const stateMachineDefinition = processJob
.next(wait10MinsTask)
.next(ddbWrite)
.next(
choiceStatement
.when(choiceCondition, conditionalMatchLambdaFunction)
.otherwise(elsePassStep)
);
Specifically focusing on our choice implementation here, you can see that we are chaining two methods together to perform the conditional logic
whendefines our if clause and action we want to performotherwisedefines our else clause and operation we want to perform
A fairly clean API in my opinion! BUT WAIT.
Remember I had mentioned above about JSON path and how important it was to understand for inputs/outputs?
Well if you were to deploy and create an execution of your state machine at the moment with the following execution input:
{
"pass": true
}
You will actually get a runtime error describing that the choice block cannot evaluate the path you’ve provided of $.pass due to it not being present within the input.
This is due to managing state between your workflow transitions. $.pass doesn’t exist on the input because of a few issues:
- The state machine has processed a number of different actions and flow operations prior to our choice
- We aren’t actually specifying what we want to do with the output of each of these actions and flow operations.
By default, the input to the next workflow item in your state machine will be the entire output of the previous workflow item. In our case, this means that the input to our choice flow operation will be the output from the DynamoDB PutItem action!
In order to solve this, we can make a small modification to the two previous action workflow items so that they don’t override the initial execution input, but rather append onto it:
const processJob = new stepFunctionsTasks.LambdaInvoke(
this,
"state-machine-process-job-fn", {
lambdaFunction: lambdaFunction,
resultPath: "$.processJobResult",
}
);
const ddbWrite = new stepFunctionsTasks.DynamoPutItem(
this,
"ddb-write-job", {
item: {
uuid: stepFunctionsTasks.DynamoAttributeValue.fromString(
crypto.randomUUID()
),
timestamp: stepFunctionsTasks.DynamoAttributeValue.fromString(
new Date().toISOString()
),
},
table: dynamodbTable,
resultPath: "$.ddbWriteResult",
}
);
The critical change here is adding the resultPath property onto the object for both our Lambda function invocation and our DynamoDB PutItem operation. This resultPath specifies where the output of the action block in question should be appended on to - in this case, I’ve just named them similarly to the variables themselves.
However with this change, the input to our choice block now looks like:
{
"pass": true,
"processJobResult": {
"ExecutedVersion": "$LATEST",
"Payload": { ... },
...
"StatusCode": 200
},
"ddbWriteResult": {
"SdkHttpMetadata": { ... },
...
}
}
So you can see that updating the action flows to include the resultPath has appended their output from the AWS service onto their own keys within the input - preserving our initial state machine execution input.
This results in our final state machine execution flowing something like:
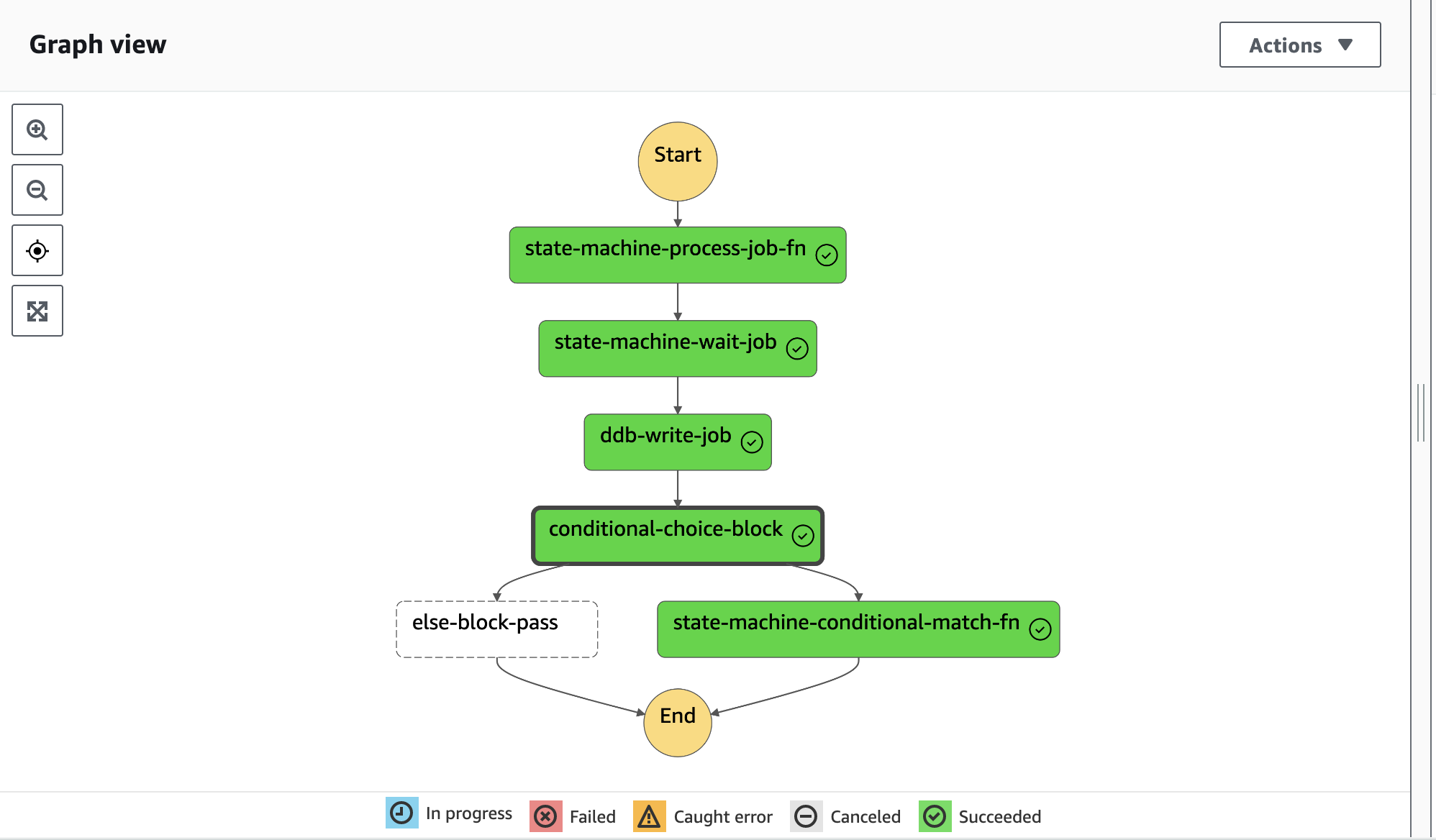
Deploy it for yourself and change the pass variable that you create an execution with and see if it flips to the other branch instead!
Remember to
cdk destroyonce you’re done to tear down the Cloudformation stack!
Conclusion
- AWS Step Functions state machine choice blocks are incredibly powerful operations that can branch your logic depending on inputs/outputs of your state machine.
- AWS CDK API for provisioning these choice blocks is straightforward and easy to use.
- JSON path is a critical piece of the puzzle when using state machines, handling their inputs/outputs and state transitions.
- Understanding how the various paths work for inputs/outputs is very important when using state machines. AWS have good documentation on the different syntax, aspects and use cases for each of these.
- They also have an interactive tool inside the AWS console itself that could be good for learning the general purpose of these - however I did find it easy to understand the concepts whenever I applied the rules to my own use case, but worth a look anyway!