How to build containerised Lambda functions with AWS CDK

AWS Lambda is at the very core whenever people mention “serverless” nowadays. The idea of being able to run isolated pieces of logic without having to really consider the compute logic under the hood is great. However, as with all AWS services, there are some limitations or quotas that need to be considered when developing.
One of these being the deployment package size when using .zip files to upload your code to the targeted lambda function - with a maximum of 50MB zipped and 250MB unzipped, this can become quite restrictive depending on your use case (e.g. including large libraries as dependencies).
With a containerised lambda, your image can be up to 10GB, which is super useful when requiring those larger libraries. Let’s take a look at how we can put one of these together using CDK.
🐳 Familiarity
Containers are pretty much part and parcel of software engineering these days. Chances are you’ve interacted with some form of Docker container, or at least have heard of them. I’m not going to go in-depth about containers as part of this blog, but the main benefit of them is the interoperability - the days of ‘works on my machine’, should be gone (in theory!).
Ultimately, this means that from a build process for something like Docker containers, it can look pretty much exactly the same whether it’s being deployed out to a dedicated container orchestration service or to Lambda.
💡 How?
So to build our containerised Lambda, there are a few pieces to the puzzle that we required. This diagram below depicts the high level overview of how the code can get deployed, and is pretty much exactly what we’re going to provision with CDK:
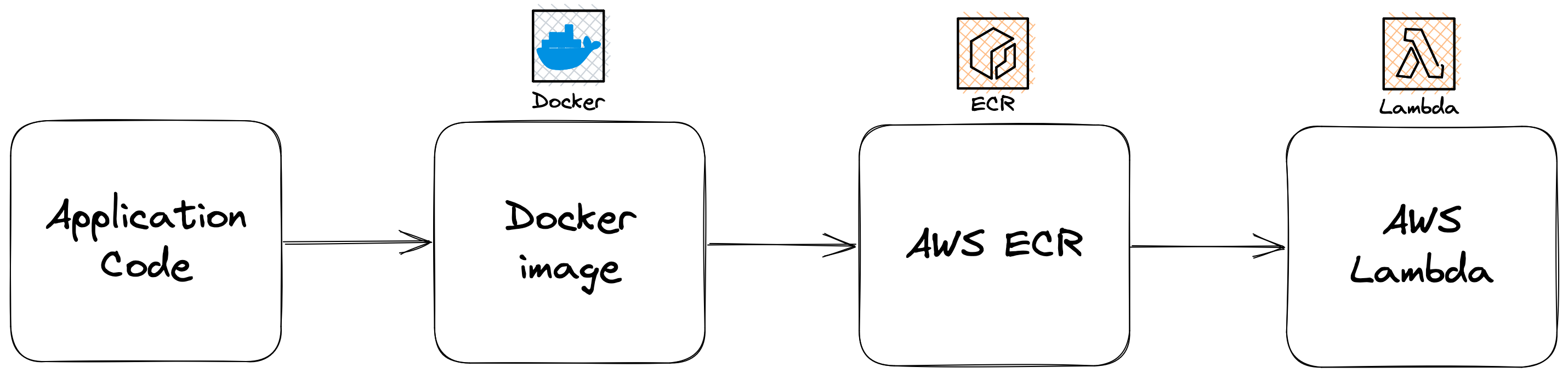
🥚 Chicken and the egg
Unfortunately, when it comes to actually provisioning the infrastructure required, we have a somewhat chicken and egg scenario in play. We need to provision our ECR repository which is going to hold the Docker image that we will build, containing the code we want to execute as part of the Lambda function. We also need to provision our Lambda function which points at said image in the ECR repo. You see where I’m going with this.
The way I approached circumnavigating this issue was to create a separate CDK stack that housed just the ECR repository. This means that it can be deployed independently, but still nicely referenced within the other CDK stack housing the lambda and everything related to it.
📦 ECR Repository
So with that, we firstly need something to house the Docker image that the Lambda can pull down. Elastic Container Registry (ECR) is AWS’ offering of the equivalent of Docker Hub. We need to provision a repository that we can push the image to.
The following code is defined in a separate CDK stack:
import * as cdk from "aws-cdk-lib";
import * as ecr from "aws-cdk-lib/aws-ecr";
import {
Construct
} from "constructs";
export class EcrStack extends cdk.Stack {
public readonly repository: ecr.Repository;
constructor(scope: Construct, id: string, props: cdk.StackProps) {
super(scope, id, props);
const stack = cdk.Stack.of(this);
const repository = new ecr.Repository(
this,
`${stack.stackName}-ecr-repo`, {
autoDeleteImages: true,
lifecycleRules: [{
maxImageCount: 10,
}],
repositoryName: "sample-application-repository",
removalPolicy: cdk.RemovalPolicy.DESTROY,
}
);
this.repository = repository;
}
}
I’ve named it EcrStack and you’ll note that I have included the ECR repository as a variable that can be accessed via the stack itself when it’s created.
Now we’re ready to build and deploy this portion of the infrastructure via the CDK CLI:
$ cdk deploy EcrStack
🔥 Build
Next, for the purposes of testing, we need to implement a very basic Lambda function handler to showcase that this works as expected. We’ll also need to wrap this functionality in a Docker container definition (Dockerfile) and expose the handler through it before finally pushing it up to our newly created ECR repository.
/**
* Lambda handle code that gets built as part of the Docker container
*/
exports.handler = async (event) => {
try {
console.log("Hello from inside containerised Lambda function!");
// Simulate success for now
return true;
} catch (err) {
console.error(err);
throw err;
}
};
Our Dockerfile can look something like the following:
FROM public.ecr.aws/lambda/nodejs:latest-arm64
COPY index.js /var/task
CMD ["index.handler"]
We’re then going to authenticate using the AWS CLI, build the Docker image and then push it up to the repository.
aws ecr get-login-password --region REGION | docker login --username AWS --password-stdin ACCOUNT_ID.dkr.ecr.REGION.amazonaws.com
docker build -t sample-application .
docker tag sample-application:latest ACCOUNT_ID.dkr.ecr.REGION.amazonaws.com/sample-application-repository:latest
docker push ACCOUNT_ID.dkr.ecr.REGION.amazonaws.com/sample-application-repository:latest
Your image should now successfully be pushed up to ECR and be ready for consumption by the lambda function.
⚡️ Lambda function
Next, we need to define the infrastructure for the lambda function. Like I mentioned above, we’re going to create a separate CDK stack for this so we can still allow the infrastructure as code to live together, but deployed independently removing the build-time dependency issue.
We’re also going to need to provision an IAM role that informs ECR that it has to provide certain permissions to Lambda in order to allow the communication to make it work.
import * as cdk from "aws-cdk-lib";
import * as ecr from "aws-cdk-lib/aws-ecr";
import * as lambda from "aws-cdk-lib/aws-lambda";
import * as iam from "aws-cdk-lib/aws-iam";
import {
Construct
} from "constructs";
interface LambdaContainerStackProps extends cdk.StackProps {
repository: ecr.Repository;
}
export class LambdaContainerStack extends cdk.Stack {
constructor(scope: Construct, id: string, props: LambdaContainerStackProps) {
super(scope, id, props);
const stack = cdk.Stack.of(this);
const lambdaRole = new iam.Role(
this,
`${stack.stackName}-lambda-execution-role`, {
assumedBy: new iam.ServicePrincipal("lambda.amazonaws.com"),
roleName: `${stack.stackName}-lambda-execution-role`,
description: "Lambda function execution role that allows the function to write to CloudWatch and read from ECR",
managedPolicies: [
iam.ManagedPolicy.fromManagedPolicyArn(
this,
"cloudwatch-full-access",
"arn:aws:iam::aws:policy/CloudWatchFullAccess"
),
iam.ManagedPolicy.fromManagedPolicyArn(
this,
"ecr-read-access",
"arn:aws:iam::aws:policy/AmazonEC2ContainerRegistryReadOnly"
),
],
}
);
const lambdaFunction = new lambda.DockerImageFunction(
this,
`${stack.stackName}-lambda`, {
code: lambda.DockerImageCode.fromEcr(props.repository),
memorySize: 128,
architecture: lambda.Architecture.ARM_64,
role: lambdaRole,
functionName: `${stack.stackName}-lambda`,
}
);
}
}
The structure of the function is going to contain some of the usual definitions you might note, but the critical change is by specifying that the code is being pulled from DockerImageCode.fromEcr, which references our newly provisioned ECR repository containing the new image.
Deploy it using the CDK CLI once more, this time specifying the lambda stack:
$ cdk deploy LambdaContainerStack
You should now successfully have a containerised lambda ready for execution!
💥 Iterate & refresh
As you iterate your application logic, you’ll want to build the images and push them up to the ECR repository. Once you complete that, you can then refresh the lambda by invoking the AWS CLI like the following:
aws lambda update-function-code --function-name LambdaContainerStack-lambda --image-uri ACCOUNT_ID.dkr.ecr.REGION.amazonaws.com/sample-application-repository:latest
This process is something I always like to include as part of CI/CD pipelines to ensure that the overhead of deployments is delegated to automation - allowing me to focus on my application logic.
Conclusion
- Containerised lambdas are incredibly useful whenever your packages are larger than the limits set out by AWS.
- CDK makes it easy to provision the resources required in order to facilitate them - but be wary of the ECR repository and Lambda function chicken and the egg situation!
- Wrapping it up in a Docker container facilitates the portability of code and promotes consistency and familiarity with software engineers.
- Be sure to tear everything down if you’ve followed along using
cdk destroy --allwhen finished!